OneGen: An AI Framework that Enables a Single LLM to Handle both Retrieval and Generation Simultaneously

A major challenge in the current deployment of Large Language Models (LLMs) is their inability to efficiently manage tasks that require both generation and retrieval of information. While LLMs excel at generating coherent and contextually relevant text, they struggle to handle retrieval tasks, which involve fetching relevant documents or data before generating a response. This inefficiency becomes particularly pronounced in tasks like question-answering, multi-hop reasoning, and entity linking, where real-time, accurate retrieval is essential for generating meaningful outputs. The difficulty lies in the fact that these models typically treat generation and retrieval as separate processes, which increases computational complexity, inference time, and the risk of error, especially in multi-turn dialogues or complex reasoning scenarios.
To address this challenge, previous approaches like Retrieval-Augmented Generation (RAG) have attempted to integrate retrieval into the generative process by retrieving relevant data and then passing it to a separate model for generation. While this two-step process enables models to generate responses based on external knowledge, it introduces significant limitations. First, it requires separate models for retrieval and generation, leading to increased computational overhead and inefficiency. Second, the two models work in distinct representational spaces, which limits their ability to interact fluidly and necessitates additional forward passes, further slowing down the process. In multi-turn conversations or complex queries, this separation also demands query rewriting, which can propagate errors and increase the overall complexity of the task. These limitations make existing methods unsuitable for real-time applications requiring both retrieval and generation.

Researchers from Zhejiang University introduce OneGen, a novel solution that unifies the retrieval and generation processes into a single forward pass within an LLM. By integrating autoregressive retrieval tokens into the model, OneGen enables the system to handle both tasks simultaneously without the need for multiple forward passes or separate retrieval and generation models. This innovative approach significantly reduces computational overhead and inference time, enhancing the efficiency of LLMs. OneGen’s key contribution is its ability to use special retrieval tokens generated during the same forward pass used for text generation, ensuring that retrieval does not compromise the model’s generative performance. This unified approach is a substantial improvement over previous methods, providing a streamlined, efficient solution for tasks that require both retrieval and generation.
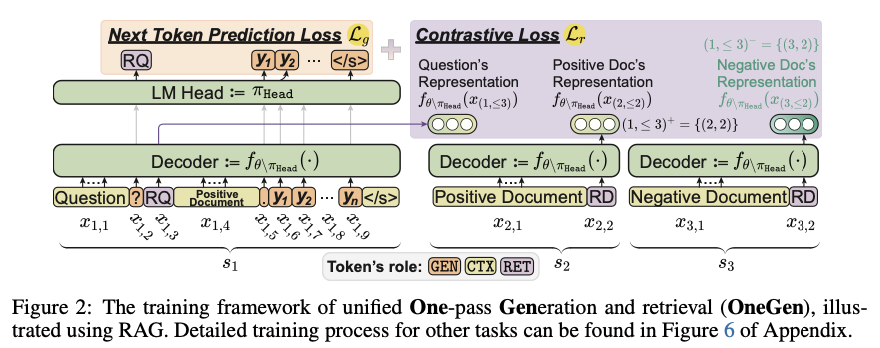
The technical foundation of OneGen involves augmenting the standard LLM vocabulary with retrieval tokens. These tokens are generated during the autoregressive process and are used to retrieve relevant documents or information without requiring a separate retrieval model. The retrieval tokens are fine-tuned using contrastive learning during training, while the rest of the model continues to be trained using standard language model objectives. This approach ensures that both retrieval and generation processes occur seamlessly in the same forward pass. OneGen has been evaluated on several datasets, including HotpotQA and TriviaQA for question-answering tasks, as well as Wikipedia-based datasets for entity linking. These datasets, which are standard benchmarks in the field, help demonstrate the versatility and efficiency of OneGen across different NLP tasks.
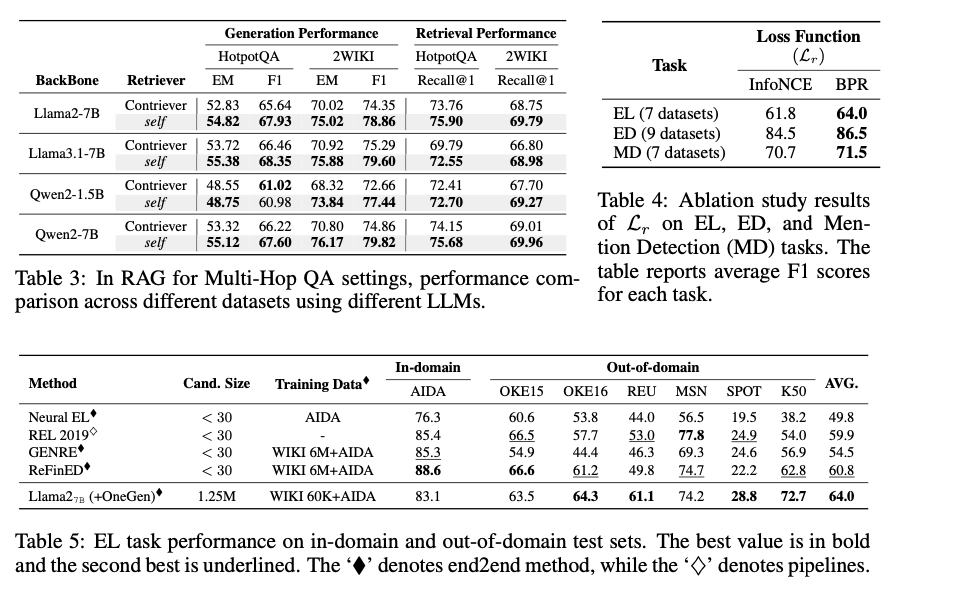
OneGen demonstrated superior performance in various tasks requiring both retrieval and generation when compared to existing models like Self-RAG and GRIT. It achieved notable improvements in accuracy and F1 scores, particularly in multi-hop question-answering and entity-linking tasks. For instance, OneGen showed a 3.2-point improvement in accuracy across six entity-linking datasets and a 3.3-point increase in F1 scores on multi-hop QA tasks. Additionally, it maintained efficient performance in retrieval tasks while enhancing the generative capabilities of the model. These results highlight the framework’s ability to streamline both retrieval and generation processes, resulting in faster and more accurate responses without sacrificing the quality of either task.
In conclusion, OneGen introduces an efficient, one-pass solution to the challenge of integrating retrieval and generation within LLMs. By leveraging retrieval tokens and utilizing contrastive learning, it overcomes the inefficiencies and complexities of previous methods that separated these tasks into distinct models. This unified framework enhances both the speed and accuracy of LLMs in tasks that require real-time generation based on retrieved information. With demonstrated improvements in performance across multiple benchmarks, OneGen has the potential to revolutionize the way LLMs handle complex tasks involving both retrieval and generation, making them more applicable to real-world, high-speed, and high-accuracy applications.



Comments
Post a Comment